Data Munging
Data was not organized in the manner that we needed to consume it. We passed
lists of films organized by date through a rest service built to query imdb.
The result is matrix of features that we used in our analysis. We used
a combination of logic written in python and java to clean and organize the
results. The code for extraction is available here Data Munging
Our Data Sets
| title | year | released | genre | rated | runtime | language | director | writer | metascore | rating | votes | budget | gross |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Danny Collins | 2015 | Apr | Comedy | R | 106 | English | Dan Fogelman | Dan Fogelman | 58 | 71 | 18347 | 10000000 | 5348317 |
| Project Almanac | 2015 | Jan | Sci-Fi | PG-13 | 106 | English | Dean Israelite | Jason Pagan | 47 | 64 | 52591 | 12000000 | 22331028 |
| Fifty Shades of Grey | 2015 | Feb | Drama | R | 125 | English | Sam Taylor-Johnson | Kelly Marcel | 46 | 41 | 209,678 | 40000000 | 166167230 |
| Blackhat | 2015 | Jan | Action | R | 133 | English | Michael Mann | Morgan Davis Foehl | 51 | 54 | 35637 | 70000000 | 7097125 |
| Stonewall | 2015 | Sep | Drama | R | 129 | English | Roland Emmerich | Jon Robin Baitz | 30 | 41 | 1176 | 13500000 | 186354 |
| How to Be Single | 2016 | Feb | Comedy | R | 110 | English | Christian Ditter | Abby Kohn | 51 | 63 | 5292 | 38000000 | 18750000 |
| Jupiter Ascending | 2015 | Feb | Action | PG-13 | 127 | English | Andy Wachowski, Lana Wachowski | Andy Wachowski | 40 | 54 | 129577 | 176000000 | 47387723 |
| The Gallows | 2015 | Jul | Horror | R | 81 | English | Travis Cluff, Chris Lofing | Travis Cluff | 30 | 43 | 11177 | 100000 | 22757819 |
| Shaun the Sheep Movie | 2015 | Aug | Animation | PG | 85 | N/A | Mark Burton, Richard Starzak | Mark Burton | 81 | 74 | 20,038 | 25000000 | 19321230 |
| Final Girl | 2015 | Aug | Action | R | 90 | English | Tyler Shields | Adam Prince | N/A | 46 | 5533 | 8000000 | 5500000 |
Collecting Data for sentiment analysis from twitter
To make the analysis more robust we decided that a column should be added
for each film that would use sentiment analysis to infer if social media
had any impact on a films success. Our list of films was feed through a
loop to make multiple rest calls to twitter's rest api. Due to limitations
in twitter data access, 100 tweets per each movie were analyzed.Positive vs Negative Sentiment
Example Data: Straight Outta Compton (2015)

The tweets were feed through a method in textblob that returned sentiment
analysis based on sophisticated implementation of Naive Bayes which returned
a score between -1 and 1.
In order to give fair scoring, only unique tweets per each movie were counted,
and sentences with neutral sentiment (usually advertisement or links) were not
counted towards calculating an average. This score was then averaged and scaled
and added to a column in our matrix of features.

Since social media tweets are unstructured sentences that contain special
characters, mispelled words and slangs, thus sorting out meaningful sentences
was a challenge. Also textblob library failed to provide accurate analysis on
sentences that contain both positive and negative words.
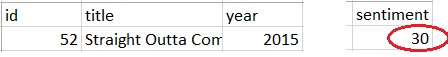
The movie Straight Outta Compton receives average sentiment score of +30.