Graphs
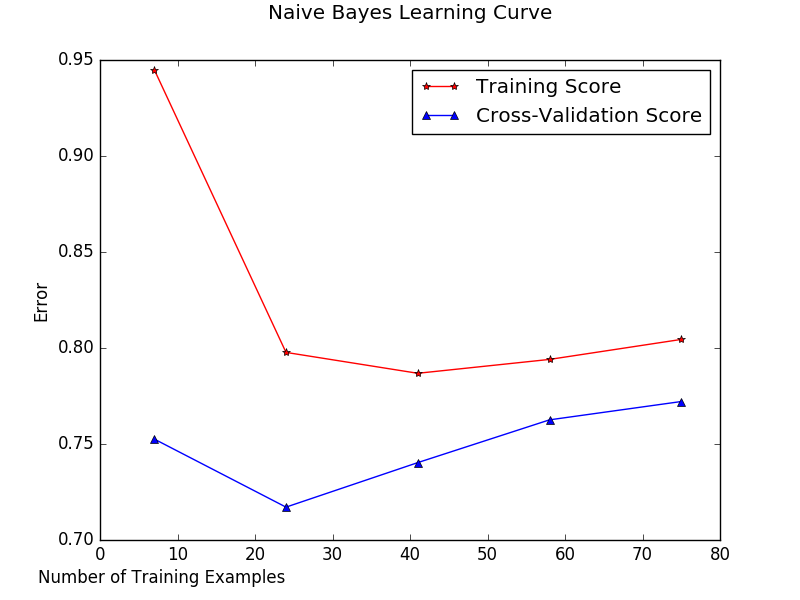
Naive Bayes
Random Forest
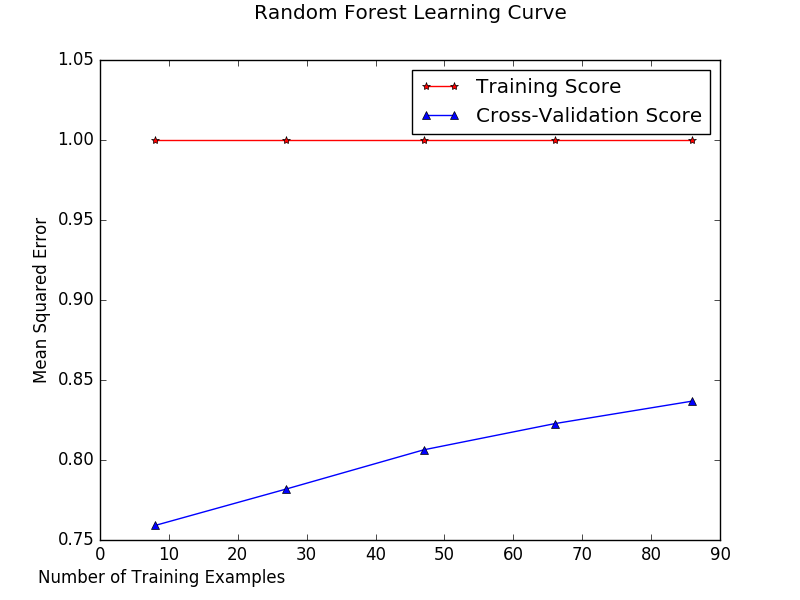
Training Curve: Artificially Restrict Training size, As training set grows, error grows.
Cross Validation: Stand in for test data, check to see if trained data is generalizable to test set. So, with increased training set size, cross validation error should decrease.
A large gap between the cross validation error curve and training error curve suggests high variance (Overfitting), cross validation error will remain high. If the cross validation error curve and training error curve are very close to each other there is high bias (Underfitting). Our study suggests that our model has some overfitting for the naive bayes classifier.
The learning curve suggests our model needs additional training data because of the high variance.
Confusion Matrix: Naive Bayes, Logistic Regression, Random Forest
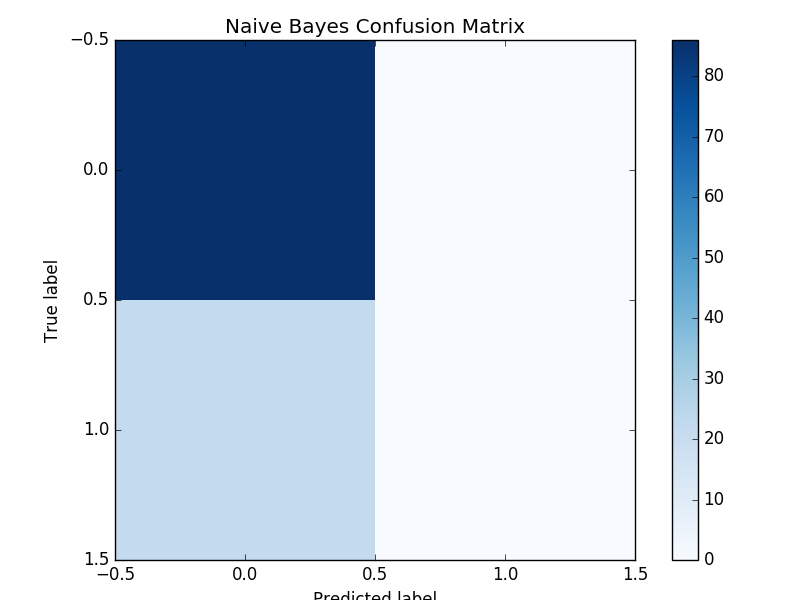
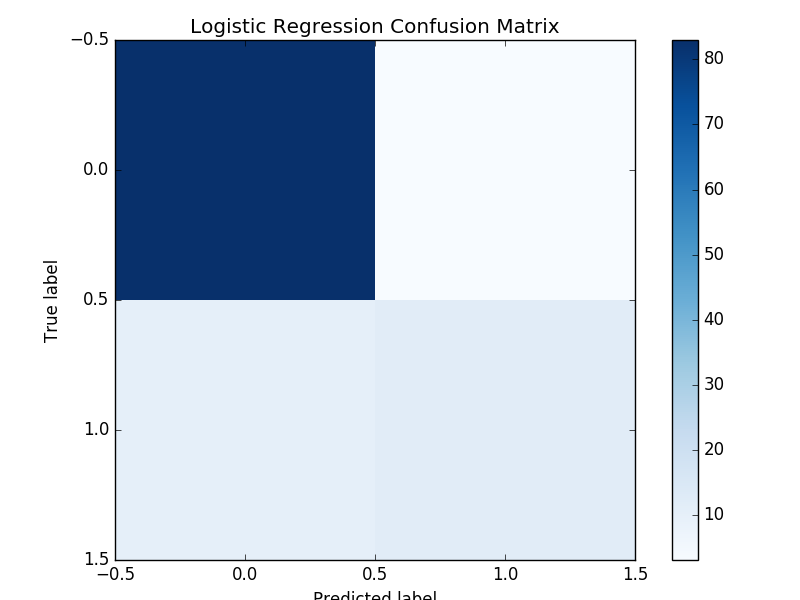
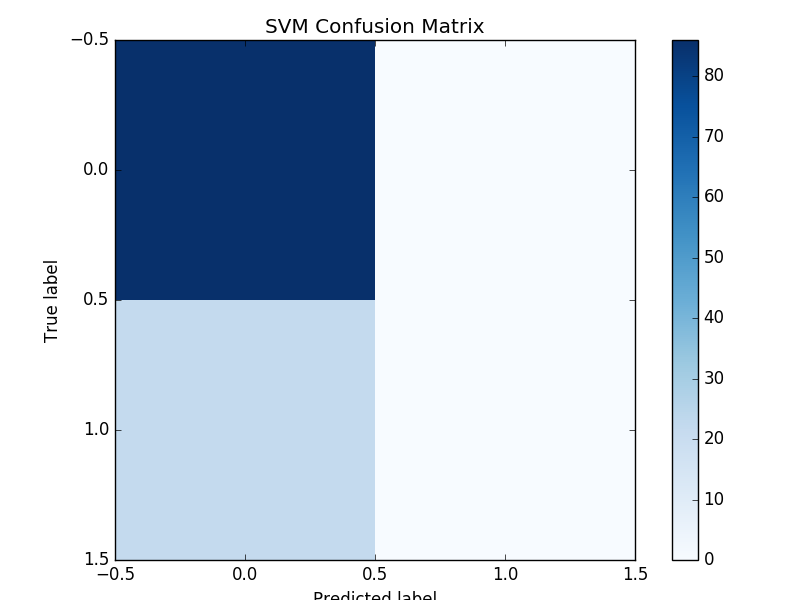
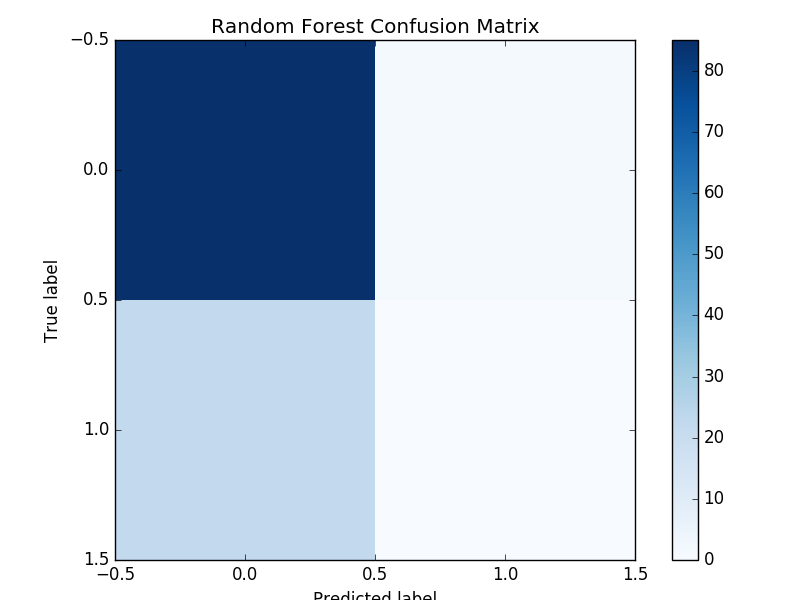
Confusion Matrix compares actual class with predicted class. In our study true negative is upper left, true positive is lower right. False negative is lower left and false positive is upper right. This shows that our classifiers often predict movies to be unsuccessful.
Receiving Operating Characteristic
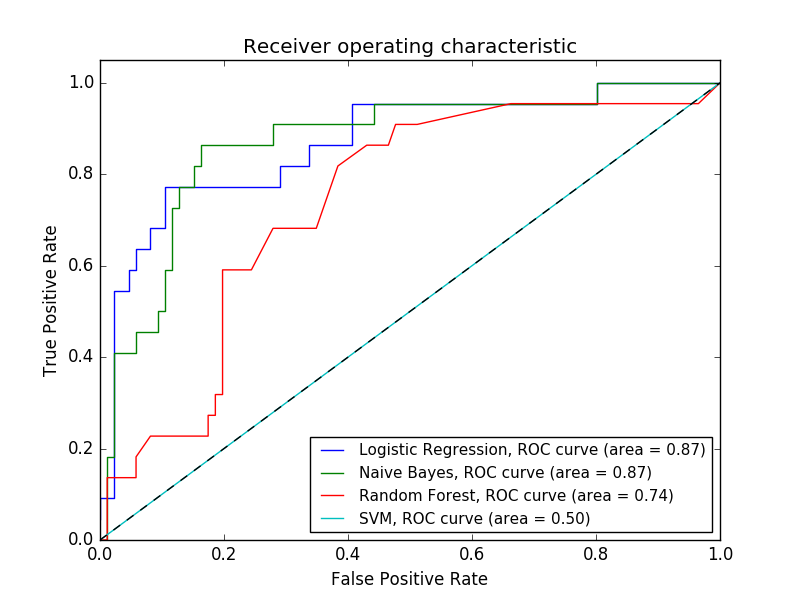
ROC Curve: common way to visual performance of binary classifier, in our study the ROC curve shows the performance of the various classifiers we used for predicting successful or not successful movies.
True Positive: When actual classification is positive how often does classifier predict positive?
False Positive: When actual classification is negative how often does classify incorrectly predict positive.
Movement along the ROC curve will give the True Positive vs False Positive rates of a given classification threshold for the classifier.
Closer to diagonal line means closer to random guessing
AUC: Area Under the Curve. Higher AUC is better, 1 is a perfect classifier, 0.5 is random guessing. For this study SVM was same as random guessing.
Strong Conclusions
- We can predict with about 70% accuracy the success of new film
- We need access to larger date sensitive data from Twitter to make this prediction more accurate
- ROC Curve shows that Naive Bayes and Logisitic Regression were the best classifiers while SVM was as bad as random guessing.
- The confusion matrix shows that the model almost always predicts movies to be unsuccessful and has a high false negative rate.
- The learning curve suggests our model requires additional training data because of the suggested high variance, especially for the random forest classifier.